Bạn đã từng nghe nói về khả năng vượt trội của Python trong lĩnh vực phân tích dữ liệu? Nếu bạn đang tìm kiếm một công cụ trực quan hóa dữ liệu dễ sử dụng, hiệu quả và tạo ra những biểu đồ đẹp mắt, thì Seaborn chính là thư viện mà bạn đang cần. Với Seaborn, việc biến đổi dữ liệu thô thành những thông tin chi tiết có ý nghĩa trở nên đơn giản hơn bao giờ hết, đặc biệt hữu ích cho các chuyên gia và những người mới bắt đầu trong lĩnh vực khoa học dữ liệu.
Seaborn: Thư viện trực quan hóa dữ liệu Python mạnh mẽ
Seaborn là một thư viện trực quan hóa dữ liệu trong Python, được phát triển bởi Michael Waskom, nổi bật với khả năng tạo ra các đồ thị thống kê chất lượng cao. Nó được xây dựng dựa trên Matplotlib nhưng cung cấp một giao diện cấp cao hơn, đơn giản hóa đáng kể quá trình tạo ra các biểu đồ phức tạp.
Sở dĩ Seaborn được nhiều nhà khoa học dữ liệu và chuyên gia phân tích ưa chuộng là vì sự cân bằng hoàn hảo giữa tính dễ sử dụng và khả năng tạo ra các biểu đồ trực quan, rõ ràng. Trong khi Matplotlib mang lại sự linh hoạt tối đa nhưng đòi hỏi cú pháp phức tạp, Seaborn lại cho phép người dùng tạo ra các biểu đồ đẹp mắt và mang tính thông tin cao chỉ với vài dòng mã lệnh. Điều này đặc biệt hữu ích cho những ai muốn tập trung vào việc khám phá dữ liệu và các khái niệm thống kê mà không bị sa lầy vào các phép tính hay cấu hình đồ thị chi tiết.
Hướng dẫn cài đặt Seaborn cơ bản
Để bắt đầu sử dụng Seaborn, việc cài đặt thư viện vào môi trường Python của bạn là rất đơn giản.
Nếu bạn đã có Python trên hệ thống của mình, cách phổ biến và tiện lợi nhất để cài đặt Seaborn là sử dụng trình quản lý gói PIP:
pip install seabornĐối với những người dùng chuyên nghiệp trong lĩnh vực khoa học dữ liệu, thường có một môi trường riêng biệt để quản lý các thư viện. Ví dụ, bạn có thể sử dụng Mamba (một công cụ quản lý gói tương tự Conda) để tạo và kích hoạt môi trường. Giả sử bạn có một môi trường tên là “stats” chứa các thư viện phổ biến khác như NumPy, SciPy và Pandas, bạn có thể kích hoạt nó bằng lệnh:
mamba activate statsSau khi cài đặt, bạn có thể chạy các lệnh Python và sử dụng Seaborn trong các môi trường tương tác như IPython hoặc Jupyter Notebook, nơi cung cấp một giao diện thuận tiện để viết và thực thi mã, đồng thời hiển thị kết quả trực quan ngay lập tức.
Chuẩn bị dữ liệu để trực quan hóa với Seaborn
Để bắt đầu trực quan hóa dữ liệu với Seaborn, bước đầu tiên là nhập thư viện và chuẩn bị dữ liệu. Theo quy ước, Seaborn thường được nhập với tên viết tắt sns để tiết kiệm thời gian gõ lệnh:
import seaborn as snsSeaborn có khả năng làm việc với nhiều định dạng dữ liệu khác nhau, nhưng phổ biến nhất là các tệp “comma-separated values” (CSV). Bạn có thể dễ dàng đọc các tệp CSV này vào một DataFrame của thư viện Pandas, một công cụ mạnh mẽ để thao tác và phân tích dữ liệu dạng bảng. Để tải một tệp CSV có tên “example.csv” trong thư mục hiện tại, bạn có thể sử dụng:
import pandas as pd
data = pd.read_csv("example.csv")Một điểm tiện lợi của Seaborn là nó tích hợp sẵn nhiều bộ dữ liệu để người dùng có thể thực hành ngay lập tức mà không cần tìm kiếm dữ liệu bên ngoài. Để xem danh sách các bộ dữ liệu có sẵn, bạn có thể dùng phương thức get_dataset_names():
sns.get_dataset_names() Danh sách các bộ dữ liệu có sẵn trong thư viện Seaborn được hiển thị trên giao diện Jupyter Notebook.
Danh sách các bộ dữ liệu có sẵn trong thư viện Seaborn được hiển thị trên giao diện Jupyter Notebook.
Trong bài viết này, chúng ta sẽ sử dụng bộ dữ liệu “tips”, chứa thông tin về các hóa đơn và tiền tip tại một nhà hàng. Để tải bộ dữ liệu này vào một Pandas DataFrame có tên tips:
tips = sns.load_dataset("tips")Để có cái nhìn tổng quan về cấu trúc và các giá trị đầu tiên của dữ liệu, bạn có thể sử dụng phương thức head() của DataFrame. Phương thức này sẽ hiển thị 5 dòng đầu tiên, giúp bạn nhanh chóng hiểu được các cột và định dạng dữ liệu:
tips.head()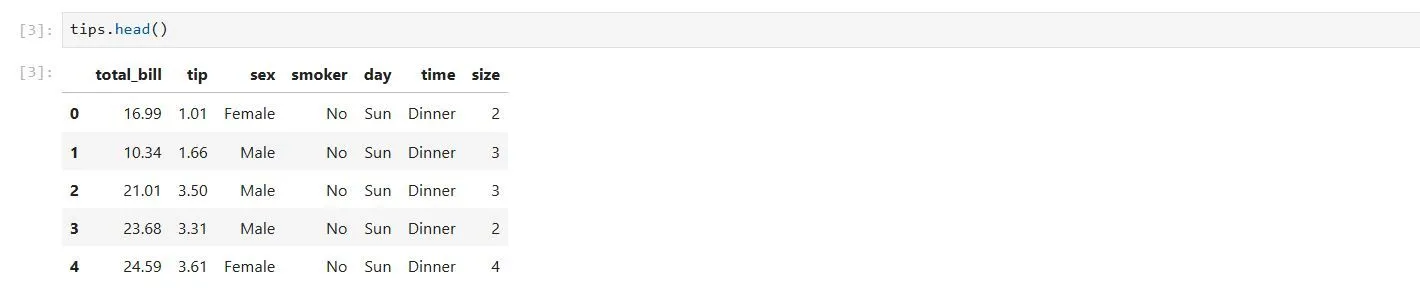 Kết quả hiển thị 5 dòng đầu tiên của tập dữ liệu 'tips' bằng phương thức head() trong Pandas DataFrame, chạy trên Jupyter Notebook.
Kết quả hiển thị 5 dòng đầu tiên của tập dữ liệu 'tips' bằng phương thức head() trong Pandas DataFrame, chạy trên Jupyter Notebook.
Khám phá dữ liệu với các biểu đồ cơ bản trong Seaborn
Seaborn cung cấp nhiều loại biểu đồ mạnh mẽ để khám phá và hiểu rõ hơn về dữ liệu của bạn. Dưới đây là ba loại biểu đồ cơ bản nhưng cực kỳ hữu ích mà bạn có thể tạo dễ dàng với Seaborn.
Vẽ biểu đồ Histogram để phân tích phân phối
Histogram là một biểu đồ cơ bản nhưng rất hữu ích, dùng để hiển thị sự phân phối của một biến số. Nó cho biết tần suất xuất hiện của các giá trị trong một phạm vi nhất định. Để tạo biểu đồ histogram cho cột “total_bill” (tổng hóa đơn) trong bộ dữ liệu tips, chúng ta sử dụng phương thức displot:
sns.displot(x="total_bill", data=tips)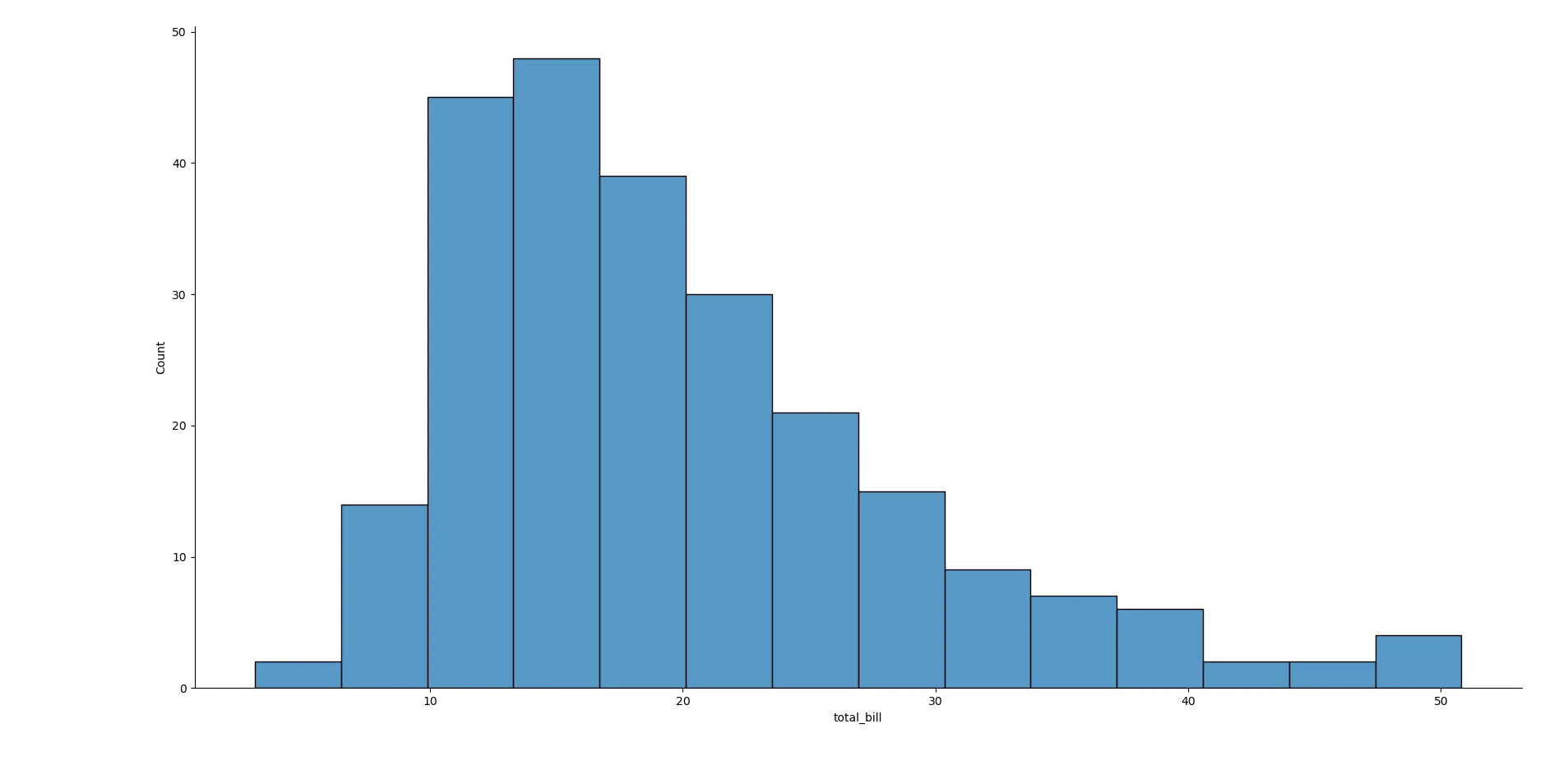 Biểu đồ Histogram thể hiện phân phối của tổng hóa đơn (total_bill) từ bộ dữ liệu 'tips' được tạo bằng Seaborn.
Biểu đồ Histogram thể hiện phân phối của tổng hóa đơn (total_bill) từ bộ dữ liệu 'tips' được tạo bằng Seaborn.
Từ biểu đồ, bạn có thể thấy rằng phân phối của “total_bill” có vẻ gần giống với một đường cong phân phối chuẩn hình chuông, nhưng có phần lệch phải (skewed to the right), với đỉnh tập trung nhiều hơn về phía trái. Điều này cho thấy phần lớn các hóa đơn có giá trị thấp hơn, và có một số ít hóa đơn có giá trị rất cao. Tham số data= là một tiện ích khi làm việc với DataFrame, giúp bạn không cần phải lặp lại tips["total_bill"] mà chỉ cần chỉ định tên cột và DataFrame nguồn.
Tạo biểu đồ Scatter Plot để nhìn thấy mối quan hệ
Một trong những điều quan trọng khi phân tích dữ liệu là tìm kiếm mối quan hệ giữa các biến số. Biểu đồ Scatter Plot (biểu đồ phân tán) là một cách tuyệt vời để trực quan hóa mối quan hệ này, bằng cách vẽ các giá trị của một cột so với một cột khác. Hãy cùng xem mối quan hệ giữa tổng hóa đơn (“total_bill”) và số tiền tip (“tip”):
sns.relplot(x="total_bill", y="tip", data=tips)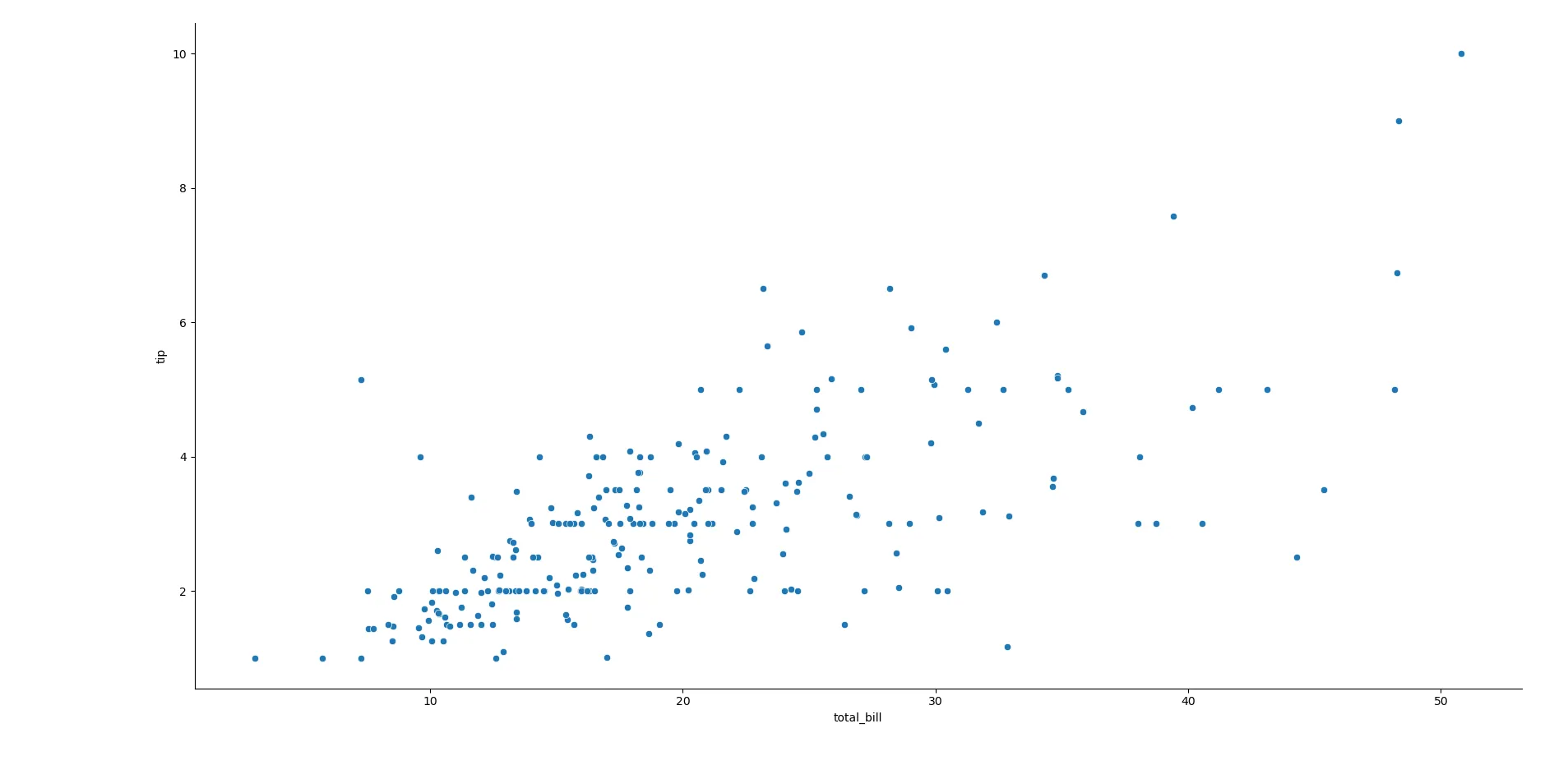 Biểu đồ Scatter Plot minh họa mối quan hệ giữa tổng hóa đơn (total_bill) và số tiền tip (tip) trong dữ liệu nhà hàng bằng Seaborn.
Biểu đồ Scatter Plot minh họa mối quan hệ giữa tổng hóa đơn (total_bill) và số tiền tip (tip) trong dữ liệu nhà hàng bằng Seaborn.
Trên biểu đồ này, trục hoành (x-axis) biểu thị tổng hóa đơn và trục tung (y-axis) biểu thị số tiền tip. Nhìn vào biểu đồ, bạn có thể nhận thấy một xu hướng rõ ràng: khi tổng hóa đơn tăng lên, số tiền tip cũng có xu hướng tăng theo.
Trực quan hóa mối quan hệ tuyến tính với Linear Regression
Nếu bạn nhìn kỹ vào biểu đồ Scatter Plot ở trên, bạn có thể thấy rằng các điểm dữ liệu dường như tạo thành một đường thẳng tưởng tượng. Điều này gợi ý một mối quan hệ tuyến tính tích cực, nghĩa là tiền tip tăng khi tổng hóa đơn tăng. Để trực quan hóa rõ hơn mối quan hệ này và tạo ra một mô hình dự đoán, chúng ta có thể vẽ một đường hồi quy tuyến tính (regression line) qua các điểm dữ liệu bằng phương thức regplot:
sns.regplot(x="total_bill", y="tip", data=tips)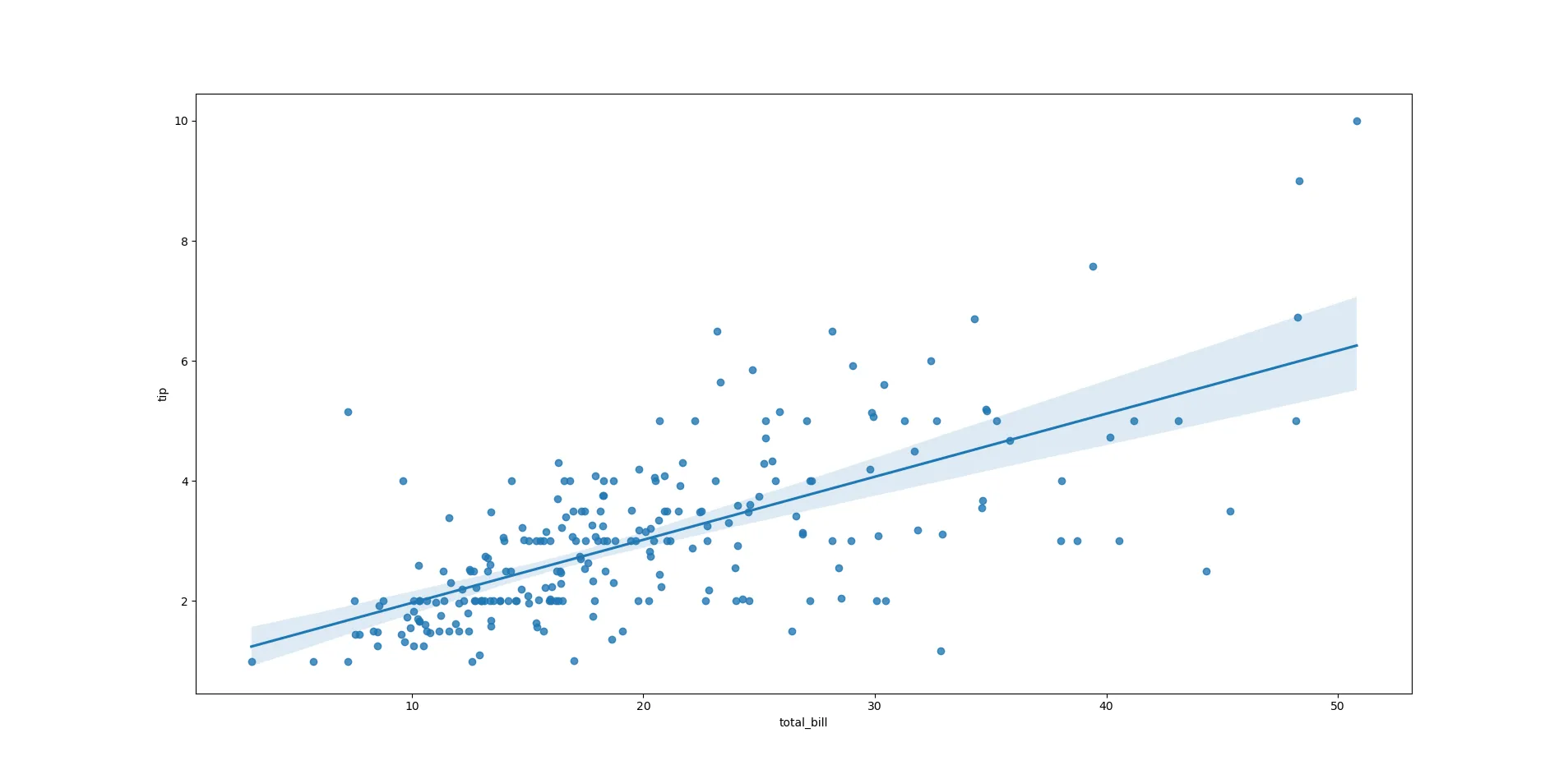 Biểu đồ hồi quy tuyến tính (Linear Regression) trong Seaborn thể hiện mối quan hệ giữa tổng hóa đơn và tiền tip, kèm theo khoảng tin cậy.
Biểu đồ hồi quy tuyến tính (Linear Regression) trong Seaborn thể hiện mối quan hệ giữa tổng hóa đơn và tiền tip, kèm theo khoảng tin cậy.
Kết quả là một biểu đồ tương tự như Scatter Plot, nhưng được bổ sung thêm một đường thẳng – đây chính là mô hình hồi quy tuyến tính “bình phương nhỏ nhất thông thường” (ordinary least-squares regression). Đường thẳng này biểu diễn mối quan hệ tuyến tính tốt nhất có thể giữa hai biến số.
Ngoài ra, bạn sẽ thấy một vùng bóng mờ phía trên và phía dưới đường hồi quy. Vùng này biểu thị khoảng tin cậy (confidence interval), cho thấy mức độ không chắc chắn của mô hình hồi quy đối với dữ liệu. Mặc dù bạn có thể tạo các mô hình phức tạp hơn, bao gồm các đường cong, nhưng điều đó nằm ngoài phạm vi của bài viết này. Hướng dẫn này chỉ là một khởi đầu nhỏ, mở ra cánh cửa để bạn khám phá và trực quan hóa dữ liệu với Python và thư viện Seaborn.
Seaborn không chỉ dừng lại ở các biểu đồ cơ bản này. Thư viện còn hỗ trợ nhiều loại biểu đồ phức tạp hơn như box plot, violin plot, heatmap và pair plot, mỗi loại đều phục vụ các mục đích phân tích khác nhau, giúp bạn có cái nhìn sâu sắc hơn về dữ liệu.
Với những kiến thức cơ bản này, bạn đã sẵn sàng bắt đầu hành trình khám phá và phân tích dữ liệu một cách trực quan hơn với Seaborn. Hãy tiếp tục thực hành, thử nghiệm với các bộ dữ liệu khác nhau và các loại biểu đồ đa dạng để nắm vững thư viện mạnh mẽ này. Đừng ngần ngại chia sẻ những phát hiện của bạn và cùng cộng đồng xalocongnghe.com tiếp tục khám phá thế giới rộng lớn của khoa học dữ liệu!